Search Questions
Search
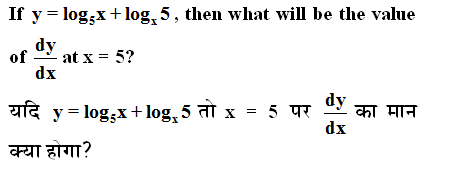
Q: Assertion (A): Reinforcement learning involves agents learning optimal behaviors through trial and error.
Reason (R): Reinforcement learning algorithms rely solely on supervised labels provided by an instructor.
Option
- A. Assertion (A) is false, but Reason (R) is true./अभिकथन (A) गलत है, लेकिन कारण (R) सही है।
- B. Assertion (A) is true, but Reason is false अभिकथन (A) सही है, लेकिन कारण (R) गलत है।
- C. Both Assertion (A) and Reason (R) are true and Reason (R) is the correct explanation of Assertion (A)./अभिकथन (A) और कारण (R) दोनों सही हैं और कारण (R) अभिकथन (A) की सही व्याख्या है।
- D. Both Assertion (A) and Reason (R) are true, but Reason (R) is not the correct explanation of Assertion (A)./अभिकथन (A) और कारण (R) दोनों सही हैं, लेकिन कारण (R) अभिकथन (A) की सही व्याख्या नहीं है।
- E. None of the above/उपर्युक्त में से कोई नहीं
Correct Answer:
Option B - सुदृढ़ीकरण (Reinforcement) सीखने में एजेंट परीक्षण और त्रुटि के माध्यम से इष्टतम व्यवहार सीखते हैं। यह तरीका व्यवहार के आधार पर पुरस्कार प्राप्त करने और उसके अनुसार अपने फैसले को संशोधित करने की प्रक्रिया को दर्शाता है। सुदृढ़ीकरण सीखने के एल्गोरिथ्म पर्यवेक्षित लेबल पर निर्भर नहीं करते हैं। इसके अलावा, यह अप्राकृतिक पर्यवेक्षण (Unsupervised Supervision) के तहत पुरस्कार संकेतों (Reward Signals) के आधार पर काम करता है। इसलिए, अभिकथन (A) सही है, लेकिन कारण (R) गलत है।
B. सुदृढ़ीकरण (Reinforcement) सीखने में एजेंट परीक्षण और त्रुटि के माध्यम से इष्टतम व्यवहार सीखते हैं। यह तरीका व्यवहार के आधार पर पुरस्कार प्राप्त करने और उसके अनुसार अपने फैसले को संशोधित करने की प्रक्रिया को दर्शाता है। सुदृढ़ीकरण सीखने के एल्गोरिथ्म पर्यवेक्षित लेबल पर निर्भर नहीं करते हैं। इसके अलावा, यह अप्राकृतिक पर्यवेक्षण (Unsupervised Supervision) के तहत पुरस्कार संकेतों (Reward Signals) के आधार पर काम करता है। इसलिए, अभिकथन (A) सही है, लेकिन कारण (R) गलत है।
Explanations:
सुदृढ़ीकरण (Reinforcement) सीखने में एजेंट परीक्षण और त्रुटि के माध्यम से इष्टतम व्यवहार सीखते हैं। यह तरीका व्यवहार के आधार पर पुरस्कार प्राप्त करने और उसके अनुसार अपने फैसले को संशोधित करने की प्रक्रिया को दर्शाता है। सुदृढ़ीकरण सीखने के एल्गोरिथ्म पर्यवेक्षित लेबल पर निर्भर नहीं करते हैं। इसके अलावा, यह अप्राकृतिक पर्यवेक्षण (Unsupervised Supervision) के तहत पुरस्कार संकेतों (Reward Signals) के आधार पर काम करता है। इसलिए, अभिकथन (A) सही है, लेकिन कारण (R) गलत है।Address
12, Church Ln, The Adelphi, Allen Ganj, Prayagraj, Uttar Pradesh 211002
+91 9554973128
info.yctbooks@gmail.com
Download Our App

